
- 搜索
日期:2025/04/03 08:12来源:未知 人气:53
2024年2月15日,OpenAI公布了文生视频大模型Sora,引发全球关注。然而,时隔近一年,Sora仍停留在PPT阶段,而亚马逊云科技已抢先发布Nova Reel,谷歌也开放了AI视频模型Veo供企业使用。在此背景下,国内互联网巨头们也纷纷布局AI生成视频领域。快手、清华大学与北京数生科技等均已推出视频生成大模型,而腾讯的AI团队也紧随其后,推出了混元文生视频大模型,并在腾讯元宝App上线。
腾讯,作为国内知名度和市值领先的互联网公司,在游戏、即时通信、移动支付等领域均有着卓越表现。此次与亚马逊云科技、谷歌等海外巨头同步推出视频生成大模型,无疑证明了其强大的技术研发实力。但真正的技术实力如何,还需通过实际体验来检验。

功能丰富但体验有待提升
腾讯混元大模型,拥有高达130亿的参数量,成为目前开源视频生成类大模型中的佼佼者。在公测期间,用户每天可享受4次标准视频生成和2次高品质视频生成的机会,且视频长度可达5秒。从功能层面来看,腾讯混元文生视频大模型相较于小雷以往体验过的同类产品,确实更加简单易懂。它提供了多样化的视频类型设置,如比例、风格、景别、光线、镜头运动等,甚至还包括流畅运镜、丰富动作和导演模式等高级功能。然而,在实际使用过程中,小雷的体验却并不尽如人意。
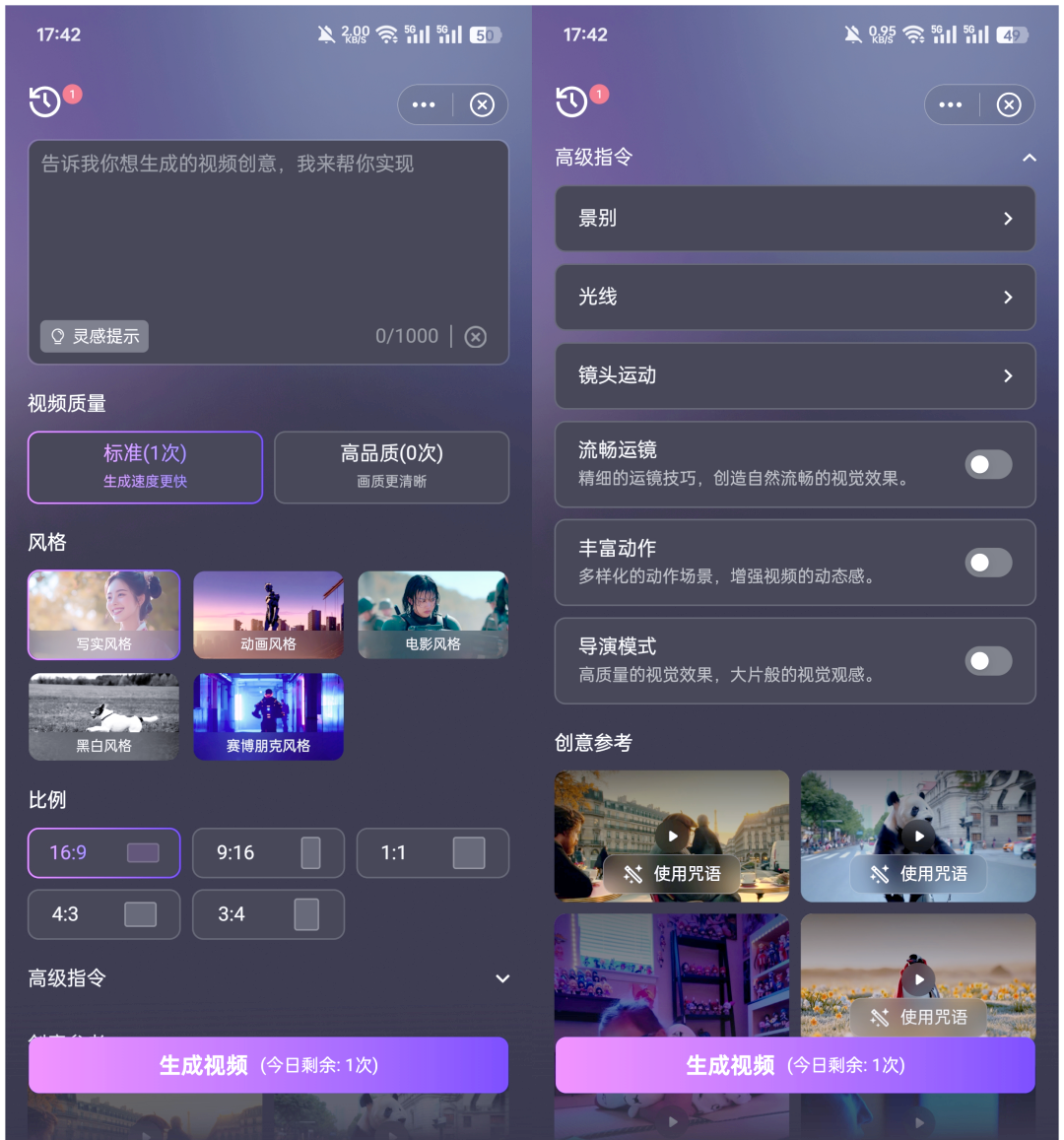 初次尝试时,小雷选择了简单的描述语:“夕阳西下,少女坐在靠窗的书桌前,眼神向上飘动,嘴角露出微笑,仿佛沉浸在一段美好的回忆中。”生成的视频效果如下:
初次尝试时,小雷选择了简单的描述语:“夕阳西下,少女坐在靠窗的书桌前,眼神向上飘动,嘴角露出微笑,仿佛沉浸在一段美好的回忆中。”生成的视频效果如下:
然而,在尝试更复杂的描述时,小雷发现腾讯混元大模型在视频生成方面仍存在一些不足。尽管功能丰富,但在实际体验中,要想生成真正符合描述、具有连贯性和生动性的视频,还需要进一步的优化和改进。
 腾讯混元大模型在视频生成方面虽有一定表现,但与小雷的预期存在差距。视频画面虽能以假乱真,却未能充分捕捉到小雷所构想的场景细节,如白人女孩的形象与预期不符,以及书桌、窗户等元素的缺失,这些都让小雷感到些许失望。特别是在考虑到腾讯拥有国内领先的短视频平台视频号所提供的丰富视频数据用于训练的情况下,这样的结果确实令人意外。不过,在尝试了“晴朗的天空,忽然乌云密布,继而骤然下起了暴雨,路上的行人有的慌忙跑到房檐下避雨,有的把挎包顶在头上一路狂奔”这一更复杂的描述后,小雷发现腾讯混元大模型在生成特定场景的视频时,其表现确实有所提升。
这段视频在初看时似乎尚可接受,但若仔细观察,便会发现其中存在不少问题。例如,部分人物的步伐显得有些飘忽,仿佛并未真正踏及地面,同时右侧一个红色的包“飘移”而过,这可能是由于AI在生成携带该包的人物时出现了失误。至于天气变化未予体现、缺乏雨感等问题,小雷已无法再作更多评论。
腾讯混元大模型在视频生成方面虽有一定表现,但与小雷的预期存在差距。视频画面虽能以假乱真,却未能充分捕捉到小雷所构想的场景细节,如白人女孩的形象与预期不符,以及书桌、窗户等元素的缺失,这些都让小雷感到些许失望。特别是在考虑到腾讯拥有国内领先的短视频平台视频号所提供的丰富视频数据用于训练的情况下,这样的结果确实令人意外。不过,在尝试了“晴朗的天空,忽然乌云密布,继而骤然下起了暴雨,路上的行人有的慌忙跑到房檐下避雨,有的把挎包顶在头上一路狂奔”这一更复杂的描述后,小雷发现腾讯混元大模型在生成特定场景的视频时,其表现确实有所提升。
这段视频在初看时似乎尚可接受,但若仔细观察,便会发现其中存在不少问题。例如,部分人物的步伐显得有些飘忽,仿佛并未真正踏及地面,同时右侧一个红色的包“飘移”而过,这可能是由于AI在生成携带该包的人物时出现了失误。至于天气变化未予体现、缺乏雨感等问题,小雷已无法再作更多评论。
在最后一轮测试中,小雷尝试了中景结合拉近镜头的拍摄方式,并选取了“宁静的海滩,满月当空,微风轻拂椰子树,发出沙沙声响。一只小猫慵懒地躺在沙滩上,细细舔舐前腿的毛发”作为描述语,生成了一段新的视频。
 这个场景虽然简洁,但同样能够检验出腾讯混元大模型的效果。在生成视频时,我特意设置了拉近镜头,以捕捉更多的细节。然而,生成的视频并未展现出镜头的动态变化,这显然是模型的一个不足之处。此外,虽然视频中的月亮和海浪细节表现不错,猫咪的形象也相当真实,但仍然未能达到我预期的效果。
这个场景虽然简洁,但同样能够检验出腾讯混元大模型的效果。在生成视频时,我特意设置了拉近镜头,以捕捉更多的细节。然而,生成的视频并未展现出镜头的动态变化,这显然是模型的一个不足之处。此外,虽然视频中的月亮和海浪细节表现不错,猫咪的形象也相当真实,但仍然未能达到我预期的效果。
为了进一步验证大模型的一致性,我再次使用相同的描述语和镜头设置生成了一段视频。这次,猫咪舔舐毛发的动作得到了体现,椰子树也出现在了画面中。然而,由于月亮的尺寸过大,给人以虚假感。同时,当猫咪移动时,沙子并未随之变化,这也暴露出模型的一些漏洞。
 小雷在探索腾讯混元大模型时,发现其给出的范例多以大量关键字描述为主,与小雷尝试的自然语言描述方式有所不同,后者无疑更具挑战性。然而,从实际表现来看,腾讯混元大模型已经展现出了对人类自然语言的理解能力,并能依据这些描述生成相应的视频。尽管细节上仍有待完善,但同一描述语两次生成的视频结果却高度相似,显示出其稳定性。
小雷在探索腾讯混元大模型时,发现其给出的范例多以大量关键字描述为主,与小雷尝试的自然语言描述方式有所不同,后者无疑更具挑战性。然而,从实际表现来看,腾讯混元大模型已经展现出了对人类自然语言的理解能力,并能依据这些描述生成相应的视频。尽管细节上仍有待完善,但同一描述语两次生成的视频结果却高度相似,显示出其稳定性。
为了更全面地了解腾讯混元大模型的水平,小雷进一步对比了Vidu和可灵两款大模型生成的视频。尽管这两款模型没有提供镜头控制功能,但通过在描述语中加入中景、拉近镜头等词汇,我们仍然能够调控生成视频的效果。Vidu生成的视频在展现小雷描述中的风吹动椰子树、猫咪舔舐毛发以及镜头拉近等细节上表现尤为出色,与小雷心中的画面高度契合。但值得注意的是,视频中的月亮过于明亮,整体色调更似清晨而非深夜,同时沙滩的质感也略显不足。
 在对比了几款大模型生成的视频后,小雷发现可灵生成的视频在细节上表现尤为出色。海浪、风吹动椰子树以及猫咪舔舐毛发等关键元素都得到了充分展现,同时,虚化和镜头拉近的运用也为视频增添了更多层次感。特别是影子的细腻变化,更是出乎意料地带来了惊喜。然而,视频中满月的缺失是一个明显的遗憾,它更像是在白天而非深夜拍摄的,这在一定程度上影响了视频的整体氛围。
在对比了几款大模型生成的视频后,小雷发现可灵生成的视频在细节上表现尤为出色。海浪、风吹动椰子树以及猫咪舔舐毛发等关键元素都得到了充分展现,同时,虚化和镜头拉近的运用也为视频增添了更多层次感。特别是影子的细腻变化,更是出乎意料地带来了惊喜。然而,视频中满月的缺失是一个明显的遗憾,它更像是在白天而非深夜拍摄的,这在一定程度上影响了视频的整体氛围。
 另外,小雷还尝试使用Vidu和可灵对另外两段描述语进行了测试,但鉴于篇幅限制,这里不再详细展示。总的来说,当前阶段的视频生成大模型已经能够理解自然语言,但面对复杂场景时仍存在不少缺陷。相比之下,在相对简单的场景下,“老牌”视频生成模型如Vidu和可灵的表现更为出色,细节处理得更为到位,而腾讯混元大模型在这方面还有显著的进步空间。
另外,小雷还尝试使用Vidu和可灵对另外两段描述语进行了测试,但鉴于篇幅限制,这里不再详细展示。总的来说,当前阶段的视频生成大模型已经能够理解自然语言,但面对复杂场景时仍存在不少缺陷。相比之下,在相对简单的场景下,“老牌”视频生成模型如Vidu和可灵的表现更为出色,细节处理得更为到位,而腾讯混元大模型在这方面还有显著的进步空间。
 混元视频大模型虽具潜力,但需腾讯深度投入
从无到有的跨越,往往比从有到优的改进更为艰难。混元大模型,在摸索中前行,其在易用性和功能性上已初露锋芒。然而,AI大模型的发展并非坦途,它不仅需要方向的指引,更需要技术的沉淀、算力的支撑以及训练数据的积累。
混元视频大模型虽具潜力,但需腾讯深度投入
从无到有的跨越,往往比从有到优的改进更为艰难。混元大模型,在摸索中前行,其在易用性和功能性上已初露锋芒。然而,AI大模型的发展并非坦途,它不仅需要方向的指引,更需要技术的沉淀、算力的支撑以及训练数据的积累。
腾讯的强大背书为混元大模型提供了坚实的财力支持,但算力的提升却需要大量的GPU和AI计算卡。在当前的AI产业环境中,GPU和AI计算卡的产能争夺日趋激烈。即便腾讯财大气粗,从堆算力到算法优化,再到大规模数据训练,每一步都需要时间来沉淀。
相比之下,Vidu和可灵等“老牌”视频生成模型已升级至5版本,不仅支持文生视频转换,更拓展了图片生成视频的功能。而初出茅庐的混元文生视频大模型,在视频生成质量上尚需时日来赶超。
 好在,混元大模型有着腾讯这一国内互联网行业领军企业的强大背书。在腾讯技术团队和资金的鼎力支持下,混元大模型有望迅速崛起。展望未来,2025年全球视频生成大模型有望迎来爆发式增长,AI生成视频的长度也将从数秒提升至分钟级,例如亚马逊云科技的Nova Reel已计划支持长达2分钟的视频生成。视频生成技术的突破将彻底释放我们的想象力,将脑海中的创意和画面变为现实。众多网络小说作家热切期待能通过AI技术将小说转化为动画或真人视频。当AI生成视频技术日趋成熟时,全球文娱产业将面临一场前所未有的革命。视频生成大模型如雨后春笋般涌现,2025年有望成为“视频生成大模型元年”,也是各家企业争霸市场的关键之年。从可灵、Vidu到腾讯混元大模型,国内企业已纷纷投身这一新兴领域,抢占新时代的先机。谁能在全球视频生成大模型行业中脱颖而出,引领行业潮流,或许不久后便可见分晓。
好在,混元大模型有着腾讯这一国内互联网行业领军企业的强大背书。在腾讯技术团队和资金的鼎力支持下,混元大模型有望迅速崛起。展望未来,2025年全球视频生成大模型有望迎来爆发式增长,AI生成视频的长度也将从数秒提升至分钟级,例如亚马逊云科技的Nova Reel已计划支持长达2分钟的视频生成。视频生成技术的突破将彻底释放我们的想象力,将脑海中的创意和画面变为现实。众多网络小说作家热切期待能通过AI技术将小说转化为动画或真人视频。当AI生成视频技术日趋成熟时,全球文娱产业将面临一场前所未有的革命。视频生成大模型如雨后春笋般涌现,2025年有望成为“视频生成大模型元年”,也是各家企业争霸市场的关键之年。从可灵、Vidu到腾讯混元大模型,国内企业已纷纷投身这一新兴领域,抢占新时代的先机。谁能在全球视频生成大模型行业中脱颖而出,引领行业潮流,或许不久后便可见分晓。

