
- 搜索
日期:2025/04/05 03:48来源:未知 人气:53
随着人工智能技术的迅猛发展,大型语言模型(LLMs)在自然语言处理、计算机视觉及科学计算等多个领域均取得了令人瞩目的成果。然而,随着模型规模的日益扩大,如何在保持高性能的同时,有效地降低资源消耗,成为了业界面临的一项重大挑战。为了迎接这一挑战,腾讯混元团队勇于创新,率先引入了混合专家(MoE)模型架构。他们最新发布的Hunyuan-Large(Hunyuan-MoE-A52B)模型,不仅成为业界目前开源的规模最大的基于Transformer的MoE模型,更拥有3890亿总参数和520亿激活参数的强大能力。
此次,腾讯混元团队还开源了三款不同规模的模型:Hunyuan-A52B-Pretrain、Hunyuan-A52B-Instruct以及Hunyuan-A52B-FP8,以满足企业及开发者在精调、部署等不同场景下的需求。这些模型均可在HuggingFace、Github等技术社区免费下载并商用。通过一系列技术优化,腾讯混元Large模型能够很好地适配开源框架的精调与部署,展现出强大的实用性。同时,腾讯云TI平台与高性能应用服务HAI也已开放接入,为模型的精调、API调用及私有化部署提供了一站式服务解决方案。
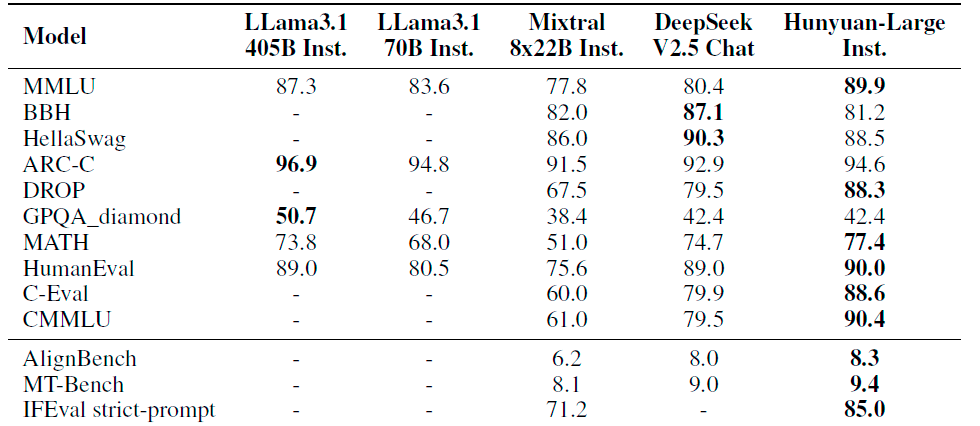
腾讯混元Large模型在CMMLU、MMLU、CEval、MATH等多学科综合评测集以及中英文NLP任务、代码和数学等9大维度上均展现卓越性能,全面超越LlamaMixtral等顶尖开源大模型。
混元Large模型采用了MoE(Mixture of Experts,混合专家模型)结构,该结构每一层都包含多个并行同构专家,使得在前向计算时,一次token只会激活部分专家。这种稀疏的网络结构不仅在性能上优于同等大小的稠密模型,还能显著降低推理成本。
在混元Large模型中,我们提出了创新的路由和训练策略。首先,通过共享专家路由策略,模型设置了一个共享专家来捕获所有token的通用知识,同时还有16个需要路由的专家,根据激活得分将token动态分配给特定领域的专家进行学习。这种策略不仅保障了训练的稳定性,还提升了模型的性能。
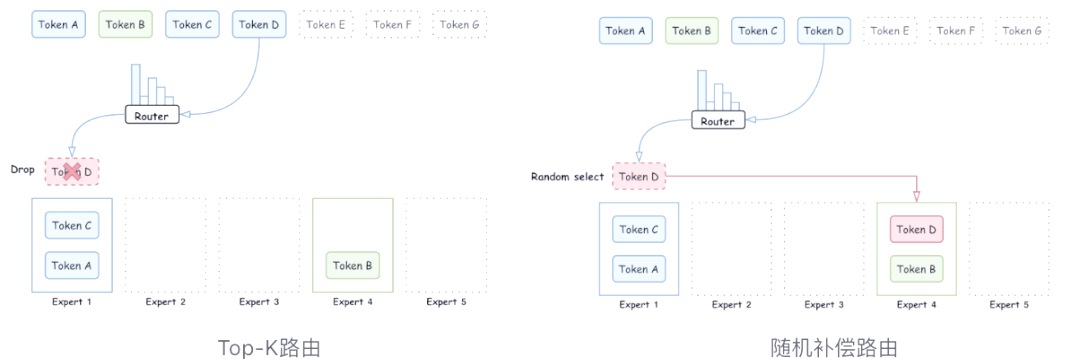
此外,我们还提出了回收路由策略来进一步优化模型的性能。路由策略是MoE模型中的关键部分,它决定了token如何被分配给各个专家。传统的Top-K路由策略可能无法确保token在专家间的均衡分配,导致部分专家训练不稳定。针对这一问题,我们提出了随机补偿的路由方式,旨在更有效地激活每个专家的能力,从而提升模型的训练稳定性和收敛速度。
通过这些技术创新,混元Large模型在保证推理速度的同时,显著提升了参数量和模型性能,为多学科综合评测集以及中英文NLP任务、代码和数学等9大维度的应用提供了强大的支持。
在混元Large模型中,由于共享专家和路由专家在每个迭代中处理的token数存在显著差异,这导致每个专家的实际batchsize并不一致。为了充分利用这一特性并提升训练效率,我们提出了专家特定学习率适配策略。根据学习率与batch size的缩放原则,我们为不同类型的专家(如共享专家和特殊专家)分别适配了不同的最佳学习率,从而确保模型能够更高效地进行训练。
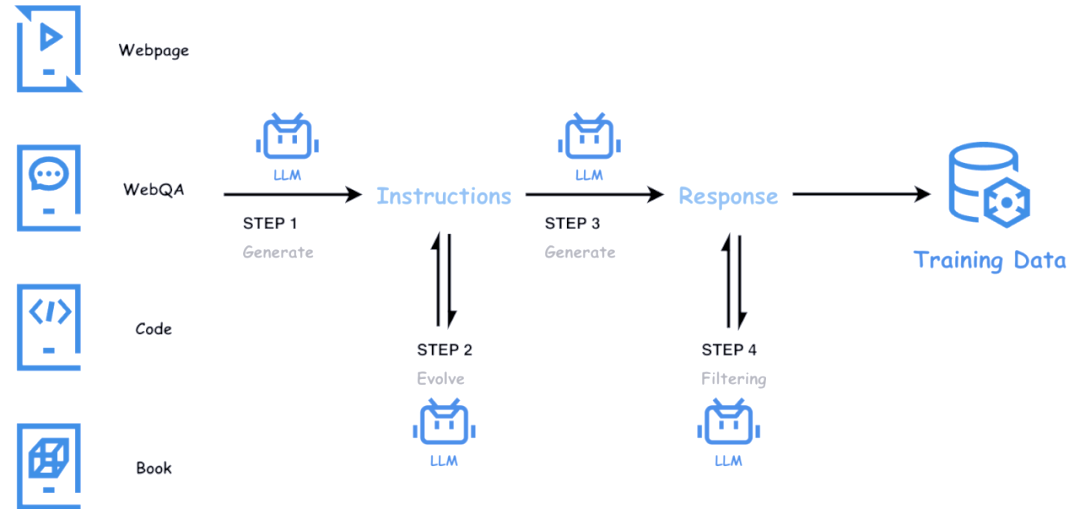
大语言模型的训练离不开高质量的数据支撑。尽管公开网页数据广泛可用,但其质量往往参差不齐,难以满足高质量训练的需求。为了解决这一问题,腾讯混元团队在天然文本语料库的基础上,巧妙地运用混元内部系列大语言模型,精心构建了大量高质量、具备多样性和高难度的合成数据。通过模型驱动的自动化方法,我们不仅对数据进行高效评价和筛选,还持续监控并维护数据质量。这一系列举措,形成了从数据获取、筛选、优化到质检和合成的完整自动化数据链路。
 在数学领域,由于网页数据中优质思维链(CoT)数据稀缺,腾讯混元Large通过从网页中挖掘并构建大规模题库,以此为种子合成数学问答,从而确保了数据的多样性。同时,我们运用一致性模型和评价模型来监控并维护数据质量,以此产出大量优质且多样的数学数据,显著提升了模型的数学能力。
在数学领域,由于网页数据中优质思维链(CoT)数据稀缺,腾讯混元Large通过从网页中挖掘并构建大规模题库,以此为种子合成数学问答,从而确保了数据的多样性。同时,我们运用一致性模型和评价模型来监控并维护数据质量,以此产出大量优质且多样的数学数据,显著提升了模型的数学能力。
在代码领域,自然代码质量参差不齐,且包含代码解释的代码-文本映射数据尤为稀缺。为此,腾讯混元Large采用天然代码库中的代码片段作为种子,合成了大量包含丰富文本-代码映射的高质量训练数据,从而大幅提升了模型的代码生成能力。
针对通用网页中的低资源但高教育价值的数据,我们通过合成方式对数据进行变换和增广,构建了大量形式多样、风格各异的高质量合成数据,有效提升了模型在通用领域的表现。
此外,我们还采用了高效的超长文Attention训练和退火策略。通过将长文与正常文本混合训练,逐步多阶段引入自动化构建的海量长文合成数据,每阶段仅需少量长文数据,即可使模型获得良好的长文泛化和外推能力。
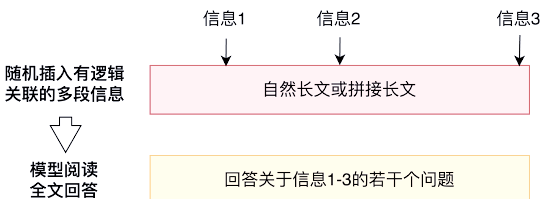 腾讯混元Large模型在长文处理方面的专项提升,已成功应用于腾讯AI助手腾讯元宝中。该模型支持最大达256K的上下文长度,这一容量足以覆盖《三国演义》或英文原版《哈利・波特》全集的内容。此外,腾讯元宝还能一次性处理多达10个文档的上传,并能够同时解析多个微信公众号链接和网址,从而赋予其独特的深度解析能力。
腾讯混元Large模型在长文处理方面的专项提升,已成功应用于腾讯AI助手腾讯元宝中。该模型支持最大达256K的上下文长度,这一容量足以覆盖《三国演义》或英文原版《哈利・波特》全集的内容。此外,腾讯元宝还能一次性处理多达10个文档的上传,并能够同时解析多个微信公众号链接和网址,从而赋予其独特的深度解析能力。
随着LLM处理序列的增长,Key-Value Cache所占据的内存逐渐增大,这给推理过程带来了成本和速度上的挑战。为了应对这一问题,腾讯混元团队采用了Grouped-Query Attention(GQA)和Cross-Layer Attention(CLA)两种策略,对KV Cache进行了有效的压缩。同时,通过引入量化技术,进一步优化了推理过程,提升了整体性能。
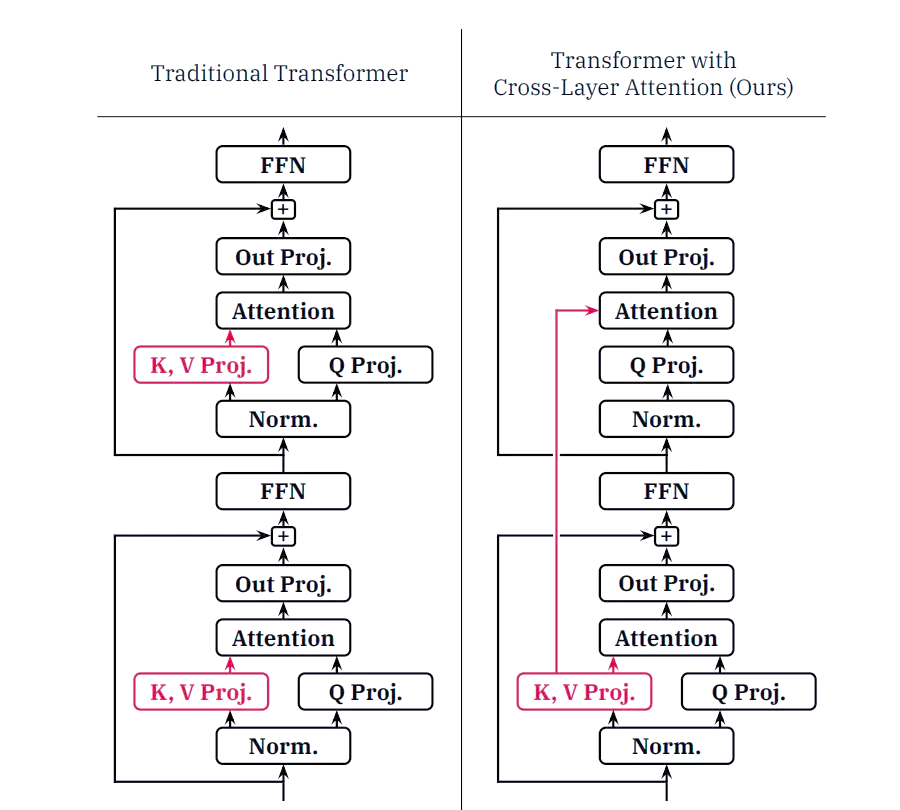 通过引入Grouped-Query Attention(GQA)和Cross-Layer Attention(CLA)策略,我们成功将Hunyuan-A52B模型的head数量从80压缩至8,同时利用CLA每两层共享KV激活值的特点,将模型的KV Cache压缩至MHA的5%,显著提升了推理性能。接下来,我们将对比不同策略下的KV Cache效果。
通过引入Grouped-Query Attention(GQA)和Cross-Layer Attention(CLA)策略,我们成功将Hunyuan-A52B模型的head数量从80压缩至8,同时利用CLA每两层共享KV激活值的特点,将模型的KV Cache压缩至MHA的5%,显著提升了推理性能。接下来,我们将对比不同策略下的KV Cache效果。
SFT 训练
腾讯混元团队在预训练的基础上,进一步利用超过百万量级的 SFT 数据对模型进行了精调。这些数据涵盖了数学、代码、逻辑、文本创作等多个领域,为模型提供了多样化的训练样本。为了确保数据质量,我们构建了一套全面的数据质检流程,包括规则和模型判别,以发现并纠正潜在的数据问题。此外,为了更高效地筛选高质量的 SFT 数据,我们基于 Hunyuan-70B 模型训练了一个 Critique 模型,它能够对指令数据进行细致的打分,从而帮助我们自动化地过滤低质数据并提升被选 response 的质量。
在 SFT 训练中,我们采用了32k的长度,并为了防止过拟合,引入了1的attention dropout和2的hidden dropout。我们发现,与Dense模型相比,采用MoE架构的模型在合理的dropout设置下,能够显著提升下游任务的评测效果。同时,通过指令数据的质量分级和分阶段训练,我们进一步提高了模型的效果。
RLHF 训练
为了使模型能够生成更符合人类偏好的回答,我们采用了直接偏好优化(DPO)算法对SFT模型进行了强化训练。与传统的离线DPO算法不同,我们设计了一种在线强化pipeline,该框架结合了固定pair数据的离线DPO策略和在线强化策略。具体来说,每一轮训练中,模型仅使用少量数据进行采样和训练。训练完成后,模型会对新数据进行采样并生成多个回答。然后,通过奖励模型(RM)对这些回答进行打分和排序,以构建偏好对并用于强化训练。
为了进一步稳定强化学习阶段的训练,我们随机选取了部分SFT数据进行sft loss的计算。由于这些数据在SFT阶段已被学习过,加入sft loss旨在维持模型的语言能力,同时确保系数设置较小。另外,为了增加dpo pair数据中优质答案的生成概率,防止DPO通过降低所有答案概率的方式来寻求简便解,我们引入了好答案的chosen loss。通过这些策略的有机结合,我们的模型在经过RLHF训练后,各项性能指标均取得了显著的提升。
腾讯混元Large模型,源自腾讯全链路自研,其训练与推理均依托于腾讯Angel机器学习平台。在面对MoE模型中的All2all通信效率挑战时,Angel训练加速框架(AngelPTM)通过多项优化措施,如Expert计算与通信层次的overlap优化、MOE算子融合优化以及低精度训练优化等,显著提升了性能,甚至超越了DeepSpeed开源框架的6倍。此外,腾讯混元Large模型还配套开源了Angel推理加速框架(AngelHCF-vLLM),该框架由腾讯Angel机器学习平台与腾讯云智能联合研发,专为混元Large模型量身定制。通过精细的量化技术,如NF4和FP8的叠加,以及并行解码优化,该框架在保持高精度的同时,成功节省了超过50%的显存,并实现了相较于BF16吞吐提升1倍以上的卓越性能。此外,Angel推理加速框架还支持TensorRT-LLM backend,进一步将推理性能提升了30%,这一成果已在腾讯内部得到广泛应用,并计划在近期推出开源版本,以惠及更多用户。

