快速入门Apache Spark:核心技术与实用指南
日期:2025/03/31 14:21来源:未知
人气:58
导读:Apache Spark,一个高效且多功能的集群计算系统,通过在内存中保存中间结果,实现了对Hadoop MapReduce的超越。后者通常会将中间结果保存在磁盘上,而Spark则能在数据尚未写入硬盘时,便在内存中完成运算。尽管Spark仅作为计算框架存在,不包含Hadoop那样的分布式文件系统和完备调度系统,但其高效性能已足够吸引人。事实上,Hadoop之父Doug Cutt......
 Apache Spark,一个高效且多功能的集群计算系统,通过在内存中保存中间结果,实现了对Hadoop MapReduce的超越。后者通常会将中间结果保存在磁盘上,而Spark则能在数据尚未写入硬盘时,便在内存中完成运算。尽管Spark仅作为计算框架存在,不包含Hadoop那样的分布式文件系统和完备调度系统,但其高效性能已足够吸引人。事实上,Hadoop之父Doug Cutting曾预言,随着大数据项目的演进,MapReduce引擎的使用将逐渐减少,而Apache Spark将成为主流。当然,现在市场上也出现了如Flink这样更能处理流式数据的系统,但Spark在大数据处理领域依旧占据一席之地。
Apache Spark,一个高效且多功能的集群计算系统,通过在内存中保存中间结果,实现了对Hadoop MapReduce的超越。后者通常会将中间结果保存在磁盘上,而Spark则能在数据尚未写入硬盘时,便在内存中完成运算。尽管Spark仅作为计算框架存在,不包含Hadoop那样的分布式文件系统和完备调度系统,但其高效性能已足够吸引人。事实上,Hadoop之父Doug Cutting曾预言,随着大数据项目的演进,MapReduce引擎的使用将逐渐减少,而Apache Spark将成为主流。当然,现在市场上也出现了如Flink这样更能处理流式数据的系统,但Spark在大数据处理领域依旧占据一席之地。
1. Spark的显著优点:
- 速度快:Spark在内存中的运算速度是Hadoop MapReduce的百倍,而基于硬盘的运算速度也大约是Hadoop MapReduce的十倍。这得益于Spark实现的RDDs DAG执行引擎,其数据缓存在内存中,支持迭代处理,显著提升了计算效率。 易上手:Spark提供了Java、Scala、Python、R以及SQL等多种语言的API,使得用户能够轻松构建并行计算程序。此外,Spark还支持超过80个高级运算符,进一步简化了编程复杂性。同时,基于Scala、Python、R和SQL的Shell提供了交互式查询功能,方便用户快速获取数据。 通用性强:Spark不仅提供了SQL执行功能,还拥有Dataset命令式API、机器学习库MLlib、图计算框架GraphX以及流计算SparkStreaming等丰富组件,构成了一个完整的技术栈,满足各种大数据处理需求。* 兼容性好:Spark能够轻松运行在Hadoop Yarn、Apache Mesos、Kubernets以及Spark Standalone等集群环境中,并且能够访问HBase、HDFS、Hive、Cassandra等多种数据库,展现出了出色的兼容性。
2. Spark中的关键组件
-
Spark-Core:作为Spark的基石,它提供了分布式任务调度和基础I/O功能。特别值得一提的是,Spark的核心功能——RDDs,正是存在于这个组件中。RDDs不仅简化了编程复杂性,其操作方式还与Jdk8的Streaming操作本地数据集合极为相似。
-
Spark SQL:在spark-core的基础上,Spark SQL引入了DataSet和DataFrame的数据抽象化概念。它赋予了用户在DataSet和DataFrame上执行SQL的能力,并提供了一种DSL,使得用户可以通过Scala、Java、Python等语言轻松操作DataSet和DataFrame。此外,Spark SQL还支持使用JDBC/ODBC服务器进行SQL语言操作。
-
Spark Streaming:利用spark-core的快速调度能力,Spark Streaming能高效运行流分析。它通过时间窗口截取小批量数据,并允许用户在这些数据上运行RDD Transformation。
-
MLlib:作为分布式机器学习的框架,MLlib提供了众多常见的机器学习和统计算法,如支持向量机、回归、线性回归、逻辑回归等。它简化了大规模机器学习的复杂性。
• GraphX:作为分布式图计算框架,GraphX提供了一套丰富的API,用于表达图计算的各种需求。同时,它还针对这些抽象化操作进行了优化,以确保高效运行。
3. Spark与Hadoop的对比
Spark作为分布式计算工具,在计算模式上与Hadoop有所不同。Spark通过将中间运算结果存储在内存中,实现了低延迟的计算,非常适合迭代计算、交互式计算以及流计算等场景。而Hadoop则基于MapReduce模型,其中间计算结果保存在HDFS磁盘上,导致延迟相对较大,更适用于大规模数据集上的批处理任务。此外,Spark的RDD组成DAG有向无环图,其API设计较为顶层,易于使用;而Hadoop的Map+Reduce模型则相对底层,算法适应性较差。在硬件要求方面,Spark对内存资源有一定的需求,而Hadoop对机器配置要求较低。
4. Spark的运行模式
类似于Hadoop的MapReduce,Spark同样提供了本地模式和线上集群模式。然而,Spark独具特色的地方在于其拥有自己的调度集群Standalone,并且兼容Hadoop的Yarn。在日常开发中,我们通常使用local本地模式,而在生产环境中,则可以选择standalone-HA或on yarn模式。
二、Spark WordCount 演示
WordCount被誉为大数据领域的“hello world”,在我们之前学习Hadoop MapReduce时,已经使用MapReduce的方式实现了它。现在,我们将基于Spark,分别用Scala、Java和Python三种语言来实现这个经典案例。以下是MapReduce实现WordCount的详细过程:
首先,在本地D:/test/input路径下,我创建了一个txt文件,内容如下:
hello map reduce abc
apple spark map
reduce abc hello
spark map
接下来,我们将分别用Scala、Java和Python三种语言,基于Spark框架实现WordCount算法,并对上述文本文件进行处理。
- Scala 语言
由于Spark的源码是用Scala语言编写的,因此使用Scala来开发Spark应用是理想的选择。对于刚开始接触Scala语言的开发者,可以通过以下教程进行学习:
https://www.cainiaojc.com/scala/scala-tutorial.html
接下来,我们将创建一个Maven项目,并在项目的pom.xml文件中加入Scala和Spark的依赖。具体如下:
org.scala-lang scala-library (此处填写具体的Scala版本号)
确保将上述代码中的`(此处填写具体的Scala版本号)`替换为实际的Scala版本号。这样,我们就可以开始使用Scala语言来开发基于Spark的WordCount应用了。
2.12.11
org.apache.sparkspark-core_2.12(此处填写具体的Spark版本号)
注意:在添加SparkCore依赖时,需要将`(此处填写具体的Spark版本号)`替换为实际的Spark版本号。这样,我们就能将Scala和Spark的依赖成功加入到Maven项目中,从而为使用Scala开发Spark应用奠定基础。接下来,我们就可以着手创建和开发基于Spark的WordCount应用了。
301
接下来,我们开始创建`WordCountScala`对象,并定义其主方法。首先,我们创建一个新的`SparkConf`对象,并设置应用程序的名称为"spark",以及运行模式为"local"。然后,我们基于`SparkConf`对象创建一个新的`SparkContext`对象,并设置日志级别为"WARN"。
接下来,我们读取位于"D/test/wordcount/"路径下的数据文件。在读取后,我们使用`filter`方法过滤掉空内容,接着使用`flatMap`和`split`方法根据空格进行拆分。最后,我们通过`map`方法对拆分后的数据进行处理。
1. 构建减值,将value固定为1。
2. 使用`reduceByKey`对数据进行处理,将同一个key下的value相加。
3. 遍历处理后的数据,并打印出每个key及其对应的value,以空格进行分隔。
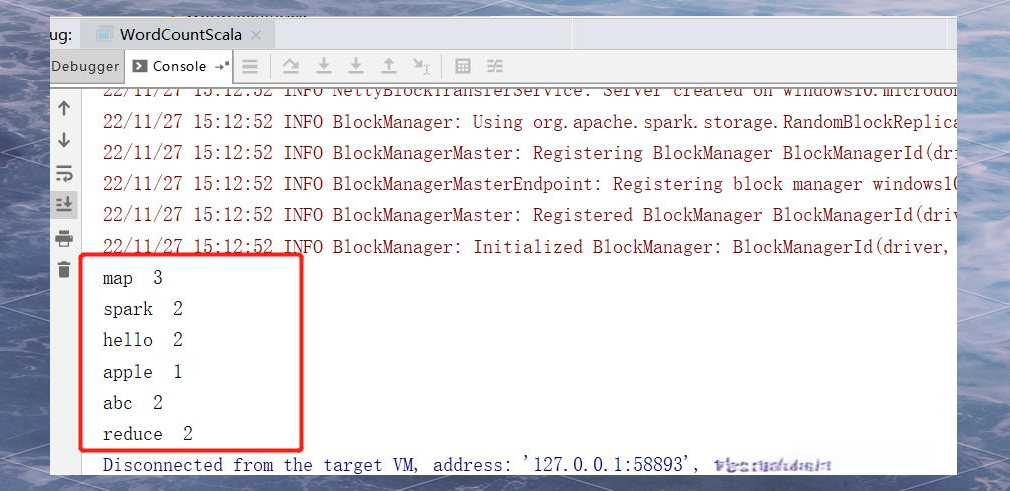
直接运行查看结果:
2\. Java 语言
由于Java和Scala都是运行在JVM之上的编程语言,我们可以在Scala的项目中直接创建Java类进行测试。接下来,我们将创建一个名为WordCountJava的测试类:
public class WordCountJava { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("spark").setMaster("local[*]"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setLogLevel("WARN"); // 读取数据 JavaRDD
textFile = sc.textFile("D:/test/wordcount/"); // 处理统计 textFile.filter(StringUtils::isNoneBlank) // 过滤空内容 .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) // 根据空格拆分 .mapToPair(s -> new Tuple2<>(s, 1)); }}
在这个示例中,我们首先创建了一个SparkConf对象来配置我们的Spark应用,并设置了应用名称和运行模式。接着,我们创建了一个JavaSparkContext对象,它提供了与Spark集群的连接。然后,我们设置了日志级别为WARN,以减少输出信息的冗余。
接下来,我们使用sc.textFile方法读取了一个位于D:/test/wordcount/路径下的文本文件,并将其存储为一个JavaRDD对象。然后,我们使用filter方法过滤掉了空内容,使用flatMap方法根据空格拆分了每一行文本,并使用mapToPair方法将拆分后的单词转换为键值对形式。这样,我们就得到了一个包含单词及其出现次数的键值对RDD。
1. 构建键值对,其中value固定为1。
reduceByKey方法的应用
使用Integer类型进行累加
将同一个key下的value值相加
foreach循环的应用
输出每个键值对,其中键为key,值为value,以空格分隔。
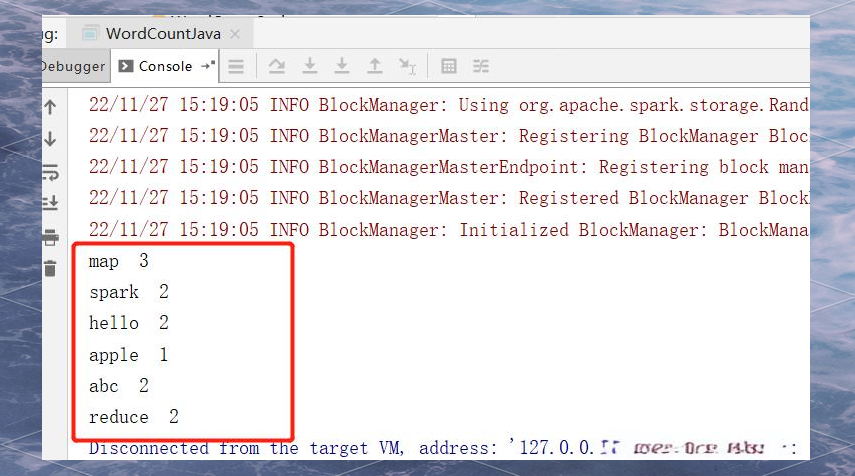
直接运行程序查看结果:
3\. Python 语言
在使用pyspark之前,需要先安装相关依赖。可以通过pip命令进行安装:
pip install pysparkpip install psutilpip install findspark
接下来,创建一个名为WordCountPy的测试脚本。在脚本中,首先导入必要的pyspark模块和findspark模块。然后,设置SparkConf对象,并指定应用程序名称为'spark',运行模式为'local[*]',并设置日志级别为"WARN"。
接下来,通过SparkContext对象读取数据。数据源为本地文件系统中的"D/test/wordcount/"路径。然后,使用filter方法过滤掉空行,再使用flatMap方法将每行文本拆分成单词。最后,使用map方法对每个单词进行处理,此处假设处理逻辑简单,直接返回单词本身。
请注意,以上代码仅为示例,并未包含完整的程序逻辑。实际使用时,需要根据具体需求进行相应的修改和扩展。
)reduceByKey(lambda v1, v2: v1 + v2)).foreach(lambda s: print(s))
这一段代码是使用pyspark进行单词计数的一个关键步骤。它通过reduceByKey方法对拆分后的单词进行分组,并使用lambda函数对每个单词进行累加操作。之后,通过foreach方法对每个分组进行迭代,并使用lambda函数打印出分组后的单词和对应的计数。这里,我们假设打印结果是一个简单的字符串,其中包含了单词和计数信息。
请注意,这段代码中的reduceByKey方法和foreach方法都是pyspark中的高级函数,它们用于对数据集进行复杂的转换和操作。此外,lambda函数在这里被用作匿名函数,用于定义简单的处理逻辑。
]+" "
+str(s[1])
这一段代码是对前一段代码的扩展,用于打印出单词和对应的计数,同时添加了一些额外的格式化信息。其中," "是一个HTML实体,用于在文本中插入非断行空格,以保持格式的整齐。而str(s[1])则用于将分组后的单词和计数信息转换为字符串格式进行打印。这里,我们假设s是一个包含单词和计数信息的元组,其中s[1]表示元组的第二个元素,即单词的计数信息。
1)))
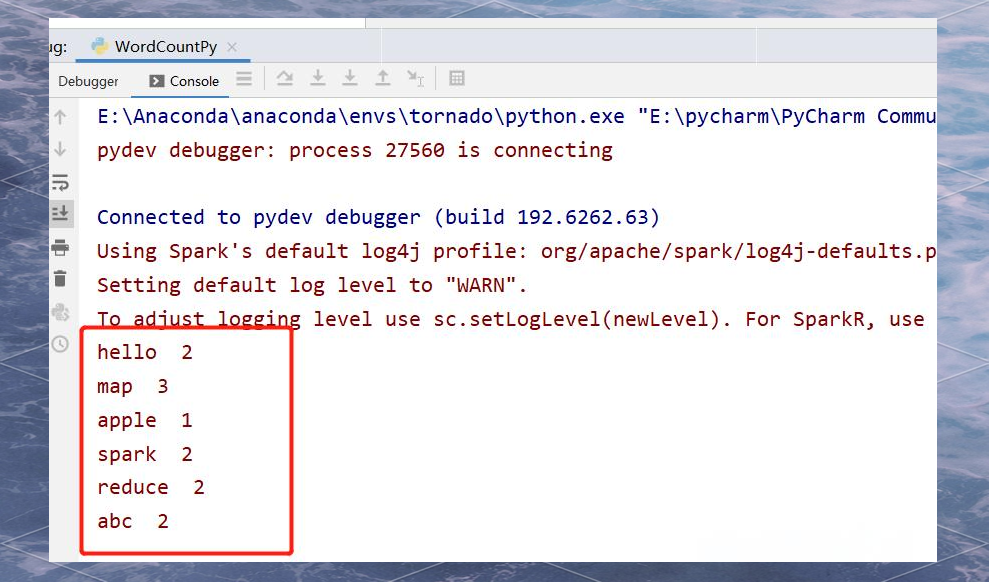
执行查看结果:
这一段代码是对前一段代码的进一步执行,用于查看并输出最终的结果。在这里,我们假设前面的代码已经进行了必要的处理和计算,现在只需要简单地执行查看结果的命令即可。具体的输出内容将取决于之前的代码和处理结果。
举报/反馈

